
The Two-Phase Pivot: How Liquid Cooling Became the Data Center’s Hardest Challenge — and the Name We’re Buying

1. INTRODUCTION: DATA CENTRES ARE BEING REINVENTED
Something fundamental is changing in how the world computes. Jensen Huang, CEO of NVIDIA, has described it plainly: data centers are no longer data centers. They are becoming token factories, industrial-scale infrastructure designed to manufacture one thing at massive throughput: AI tokens. Every query answered, every image generated, every agent task completed produces tokens. The data center is the factory floor. It is important to understand the impact of this to see the real opportunity in AI Datacenters in general, and two-phase liquid cooling, the solution that this company is bringing to market.
1.1 From Human-Paced to Agent-Paced Compute
The way we use computers today is intermittent. A person opens a browser, types a few keywords into a search engine, clicks through several links, reads and synthesizes the relevant information themselves, and closes the tab. The computer is idle most of the time. Computing in this model is reactive, it responds when you ask, then waits.
The shift already underway changes this at its root. Prompting is becoming the new search. Instead of typing keywords and sifting through ten blue links, users describe what they want in plain language and the AI finds, reads, synthesizes, and delivers an answer directly. This alone multiplies token generation: a single prompt triggers not one lookup but dozens of retrievals, reasoning, and generation steps happening in parallel.
But that is only the first stage. The more transformative shift is from prompting to delegating. An AI agent is not a search engine that gives better answers. It is a digital worker that takes actions on your behalf, autonomously, continuously, and at a scale no human team could match. Consider the difference in practice:
Table 2: From Human-Paced to Agent-Paced Compute — Paradigm Shift Summary
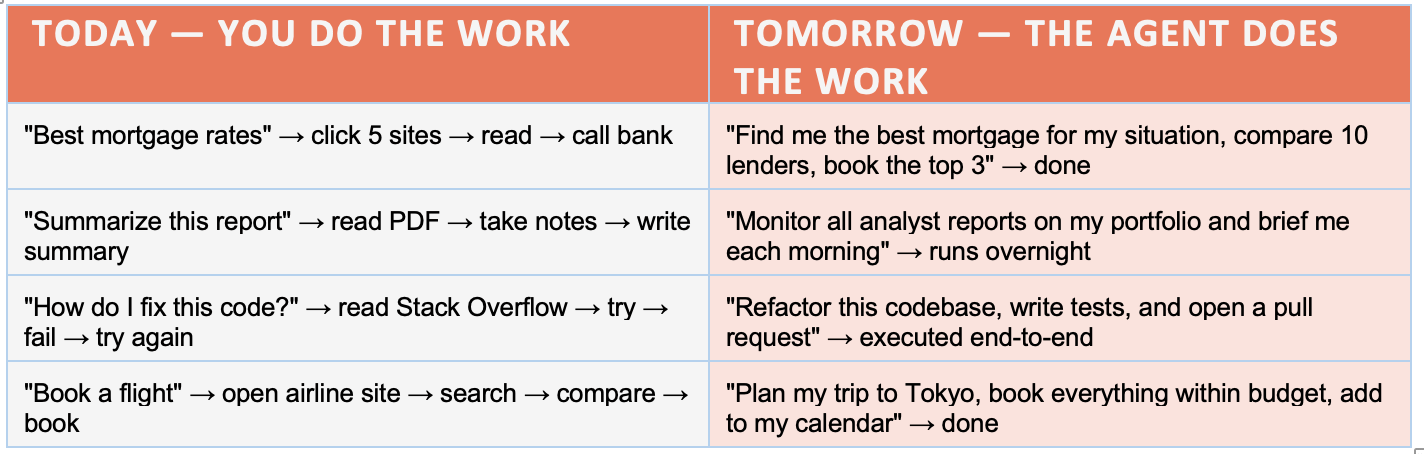
Each of these agent tasks does not generate one inference call, it generates hundreds. The agent searches, retrieves, reasons, drafts, checks, revises, and acts, spawning sub-agents along the way. A request that once produced a single API response now produces a cascade of thousands of tokens across multiple parallel workstreams. Jensen Huang has framed this precisely: every company will have AI agents running their operations. Customer service, finance, legal, coding, research, hiring, all running continuously, in parallel, around the clock. The office never closes. The compute never idles.
This is the step-change that makes the data center buildout structurally different from every prior technology wave. It is not that more people will use computers. It is that the agents those people deploy will use computers at a scale order of magnitude beyond anything a human workforce generates, and they will do so 24 hours a day, every day.
This is why Microsoft, Google, Meta, and Amazon have collectively committed over $300 billion in data center capital expenditure in 2025 alone. They are not building for the queries sent today. They are building for the agents that will run tomorrow, continuously, in parallel, at a scale no human workforce could match.
1.2 NVIDIA’s Chip Roadmap and the Thermal Cliff
At the center of this buildout sits NVIDIA, which has committed to a one-year GPU release rhythm: Hopper (H100) → Blackwell (B200) → Vera Rubin → Feynman. Each generation roughly doubles compute density. Each generation produces more tokens per rack. And each generation creates a thermal challenge that the previous generation’s infrastructure cannot solve:
Figure 1: NVIDIA GPU Generation Power Roadmap — TDP Scaling from H100 to Next-Generation Blackwell Ultra
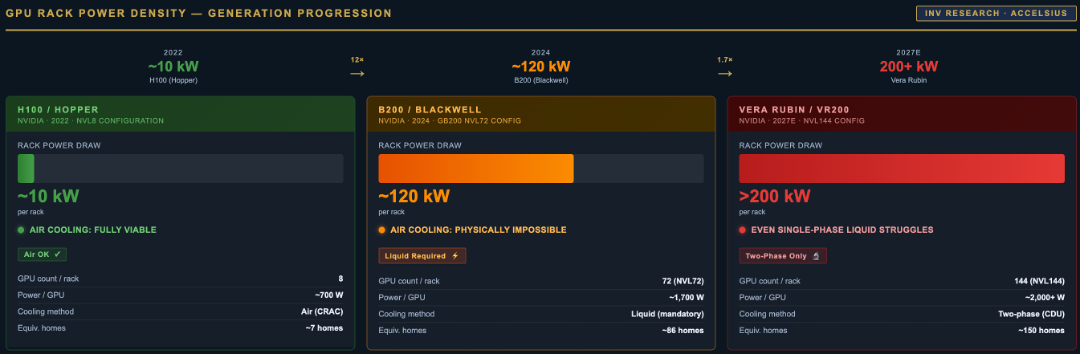
This is not a gradual transition. It is a cliff. And there is a critical design constraint that makes it non-negotiable: GPUs must be physically close to one another to communicate at NVLink speeds. They cannot be spread across a building. Density is an architectural requirement, not a preference, and density at this scale generates heat that only one class of cooling technology can manage.
Figure 2: Data Centre Thermal Wall — Power Density Growth and Cooling Transition Threshold

1.3 Why This Creates a Structural Opportunity
The combination of agent-paced compute demand, NVIDIA’s chip roadmap, and the physics of heat removal at scale creates what infrastructure investors call a forced purchase. A hyperscaler committing $500 million to a Vera Rubin cluster will spend a fraction of that on cooling infrastructure. Without it, chips throttle. Clock speeds reduce automatically to stay within safe temperature limits, and the $500 million investment can deliver 30–50% less performance than its nameplate. No COO/CFO in the world declines that policy. The cooling system is not a cost center. It is the performance guarantee on the entire data center investment.
It is against this backdrop that this company should be understood. This company does not sell a nice-to-have product in a growing market. It sells the infrastructure that makes the $300 billion AI data center buildout work at full capacity.
2. Investment Thesis
The company we're buying is an industrial holding company built on a single insight: the world's largest corporations routinely develop breakthrough technologies they lack the focus or incentive to bring to market. Rather than inventing from scratch, this company licenses proven but dormant IP from blue-chip multinationals and household names in consumer goods, telecoms, and chemicals. Then builds dedicated companies around each technology, retaining significant ownership stakes as those businesses scale.